
Kubernetes Cloud Native Monitoring with TICK & Prometheus - Up and Running


0 Introduction
This post doesn't intend to introduce prometheus or influxdb, it serves as a reference for building up a monitoring/logging system in kubernetes with open source softwares.
The monitoring/logging/alerting system composes of 4 open sources softwares, refer to diagram below

- Fluentbit is used for log collecting, fluentbit is deployed as kubernetes daemonset to all kubernetes nodes, it collects container's log and enriches them with metadata from kubernetes API.
- InfluxDB is used to store collected/enriched logs from fluentbit.
- Prometheus is used for monitoring, it pulls metrics from service monitoring targets and store metrics to its own time series database.
- Granfa is used for metris analytics & visualization, it serves as a dashboard system.
1 Prerequisites
The whole deployment requires helm, charts and a few of customized configuration files, follow below steps to download them in advance
1.1 Helm
Refer to Install applications with Helm in Azure Kubernetes Service (AKS), install helm
1.2 TICK Charts
Clone TICK charts from below repository
git clone https://github.com/influxdata/tick-charts.git
TICK stands for
- T - Telegraf
- I - InfluxDB
- C - Chronograf
- K - Kapacitor
1.3 Monitoring Configuration Files
Download kubernetes monitoring configuration files from below repository
git clone https://github.com/huangyingting/k8smon.git
2 Install/Configure TICK Stack & Fluentbit for Logging
2.1 Install TICK Stack
From command prompt/shell, change directory to tick-charts(cloned from section 1.2)
helm install --name data --namespace tick ./influxdb/ --set persistence.enabled=true,persistence.size=16Gi,config.udp.enabled=true
helm install --name alerts --namespace tick ./kapacitor/ --set persistence.enabled=true,persistence.size=8Gi
helm install --name dash --namespace tick ./chronograf/
helm install --name polling --namespace tick ./telegraf-s/
2.2 Configure InfluxDB UDP Port
The default setting of influxdb is incorrect for udp service, we need to change protocol from TCP to UDP with below steps
kubectl edit service data-influxdb -n=tick
Modify
- name: udp
port: 8089
protocol: TCP
targetPort: 8089
To
- name: udp
port: 8089
protocol: UDP
targetPort: 8089
2.3 InfluxDB Configuration
From command prompt/shell, run kubectl port-forward svc/dash-chronograf -n=tick 8080:80
Open a brower and access URL http://localhost:8080, follow the wizard set
- InfluxDB address to http://data-influxdb.tick:8086
- Kapacitor address to http://alerts-kapacitor.tick:9092
From "InfluxDB Admin", create two database called "fluentbit" and "telegraf" with below settings
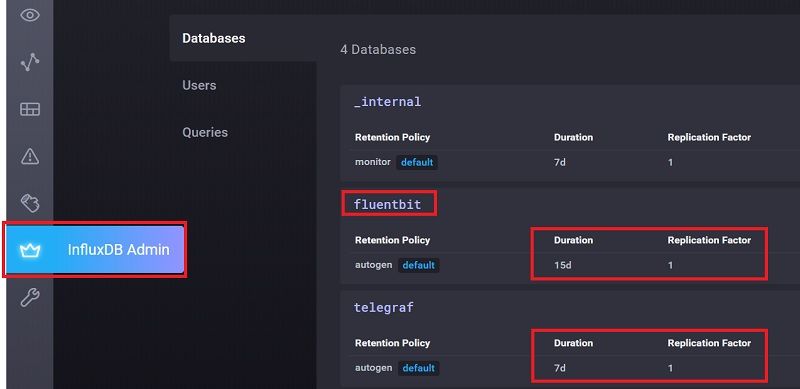
2.4 Install Fluentbit to Collect Container's Log
Fluentbit is a lightweight log collector, according to Fluentbit
Fluent Bit is an open source and multi-platform Log Processor and Forwarder which allows you to collect data/logs from different sources, unify and send them to multiple destinations. It's fully compatible with Docker and Kubernetes environments.
Fluentbit is used here to collect and populate kubernetes container logs to influxdb, to install it into kubernetes, change directory to k8smon
kubectl create namespace logging
kubectl apply -f fluentbit-config.yaml
kubectl apply -f fluentbit-ds.yaml
2.5 Verify Log Collecting
Fluentbit should start to collect container's logs and store them into influxdb, to verify it works appropriately, from chronograf "Explore", hightlight database "fluentbit", it should list containers measurements like below
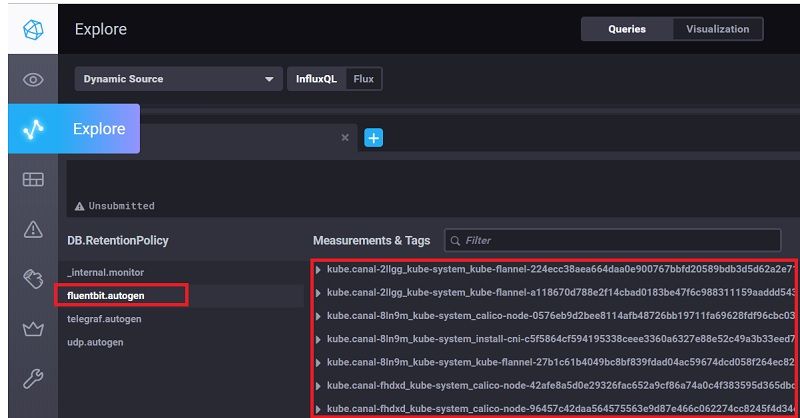
3 Install/Configure Prometheus for Monitoring
Prometheus is an open-source systems monitoring and alerting toolkit originally built at SoundCloud.
We choose prometheus operator as it has a set of pre-configured dashboards and alerts.
3.1 Install Prometheus Operator
Change directory to k8smon, then from command prompt/shell, run
helm install --name prom --namespace prom stable/prometheus-operator -f prometheus_values.yaml
3.2 Configure ETCD Monitoring
Newest kubernetes cluster shold have SSL/TLS enabled for ETCD, prometheus needs to have a client certificate to monitor ETCD, for example, in a kubeadm setup cluster, client certificate/key/ca certificate are in master node's directory /etc/kubernetes/pki/etcd, copy/rename CA certificate to ca.crt, etcd client certificate to etcd.crt and etcd client key to etcd.key, then create a yaml with below commands
cat <<-EOF > etcd-client-cert.yaml
apiVersion: v1
data:
etcd-ca.crt: "$(cat ca.crt | base64 --wrap=0)"
etcd-client.crt: "$(cat etcd.crt | base64 --wrap=0)"
etcd-client.key: "$(cat etcd.key | base64 --wrap=0)"
kind: Secret
metadata:
name: etcd-client-cert
namespace: prom
type: Opaque
EOF
And apply it to kubernetes cluster
kubectl apply -f etcd-client-cert.yaml
3.3 Configure Controller Manager and Scheduler Monitoring
Monitoring kubernetes controller manager and scheduler requires they are listening at 0.0.0.0 address, if kubernetes is deployed with kubeadm, we need to change following settings and then reboot master node
sed -e "s/- --address=127.0.0.1/- --address=0.0.0.0/" -i /etc/kubernetes/manifests/kube-controller-manager.yaml
sed -e "s/- --address=127.0.0.1/- --address=0.0.0.0/" -i /etc/kubernetes/manifests/kube-scheduler.yaml
3.4 Configure Telegraf Ouput to Prometheus
We'd like to use prometheus to collect influxdb's metrics and have influxdb monitored by prometheus, unfortunately influxdb doesn't expose its metrics to prometheuse. However, telegraf can collect influxdb's metrics and output to prometheus, so we can configure telegraf to transit influxdb metrics to prometheus, to do that, change directory to tick-charts, from command prompt/shell, run
helm upgrade polling --namespace tick ./telegraf-s/ -f ../k8smon/telegraf_values.yaml
3.5 Verify Monitoring
Prometheus should start to collect metrics, to verify it works appropriately, from command prompt/shell, run
kubectl port-forward svc/prom-prometheus-operator-prometheus -n=prom 9090:9090
Now, open a browser and visit
http://localhost:9090/targets
All targers should be green
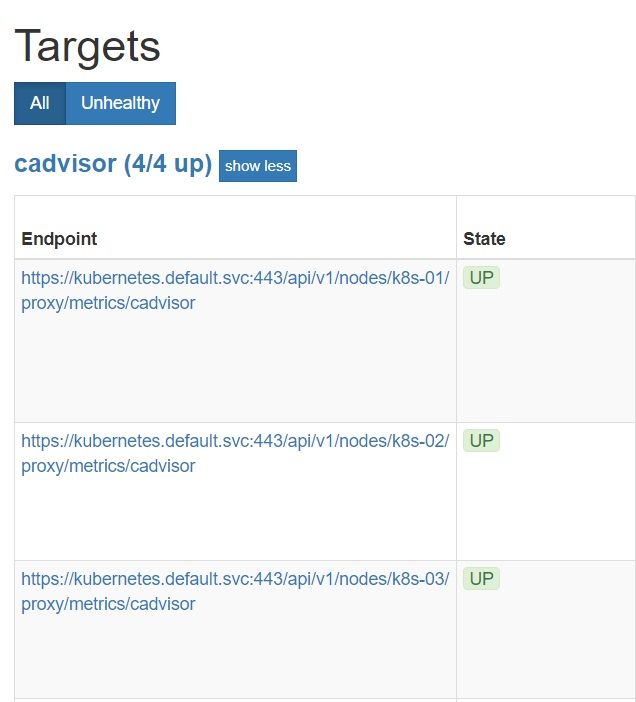
Also, accessing http://localhost:9090/graph, all metrics should be populated
4 Alerting
Refer to Alerting overview
Alerting with Prometheus is separated into two parts. Alerting rules in Prometheus servers send alerts to an Alertmanager. The Alertmanager then manages those alerts, including silencing, inhibition, aggregation and sending out notifications via methods such as email, PagerDuty and HipChat.
The default configuration in prometheus_values.yaml will redirect alerts to a null notification channel.
config:
global:
resolve_timeout: 5m
route:
group_by: ['job']
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receiver: 'null'
routes:
- match:
alertname: Watchdog
receiver: 'null'
receivers:
- name: 'null'
To enable sending alerts to MSTeams, we can
- From prometheus_values.yaml, comment out above configurations and uncomment below part
route:
group_by: ['alertname', 'job']
group_wait: 30s
group_interval: 1m
repeat_interval: 12h
receiver: 'prometheus-msteams'
routes:
- match:
alertname: Watchdog
receiver: 'prometheus-msteams'
receivers:
- name: 'prometheus-msteams'
webhook_configs:
- send_resolved: true
url: 'http://prometheus-msteams.prom:2000/alertmanager'
- Run
helm upgrade prom --namespace prom stable/prometheus-operator -f prometheus_values.yamlto update the settings - Clone prometheus-msteams with
https://github.com/bzon/prometheus-msteams.git - From MSTeams, correct a webhook for a channel, then open values.yaml, set alertmanager to webhook URL
connectors:
- alertmanager: https://outlook.office.com/webhook/xxx/IncomingWebhook/xxx/xxx
- Run
helm install --name prometheus-msteams ./prometheus-msteams --namespace promto install prometheus-msteams
If it is configured correctly, you should be able to receive alerts from prometheus in MSTeams

Prometheus has an alert manager to review all alerts, it can be accessed with
kubectl port-forward svc/prom-prometheus-operator-alertmanager -n=prom 9093:9093
Then open a browser to http://localhost:9093/#/alerts
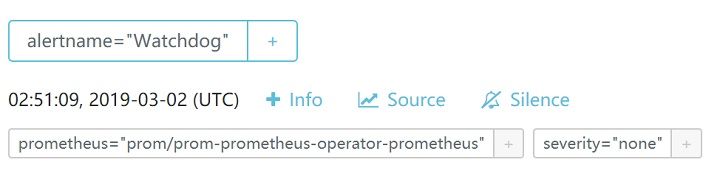
5 Grafana
The default setup will install a few of pre-configured dashboards into grafana, to access those dashboard, we need to login to grafana first,
- Follow below steps to get username/password
kubectl get secret -n=prom prom-grafana -o jsonpath="{.data.admin-user}"|base64 --decode;echo
kubectl get secret -n=prom prom-grafana -o jsonpath="{.data.admin-password}"|base64 --decode;echo
- Run
kubectl port-forward svc/prom-grafana -n=prom 18080:80, and open browser to access http://localhost:18080/login, login with username/password retrieved from step 1. - From "Home", find those pre-configured dashboards
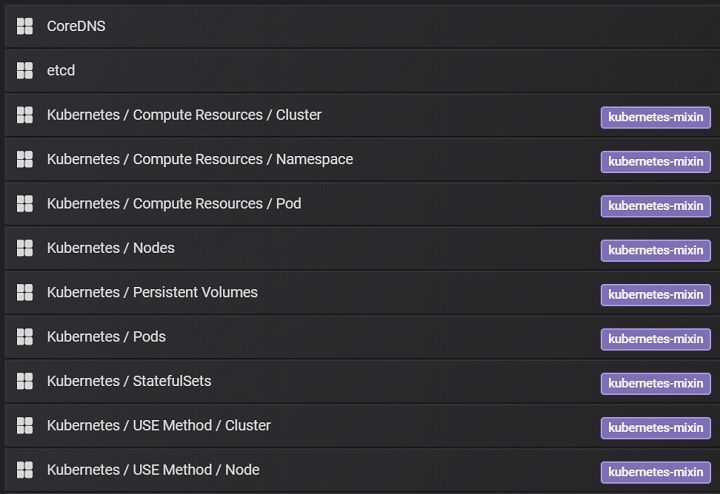
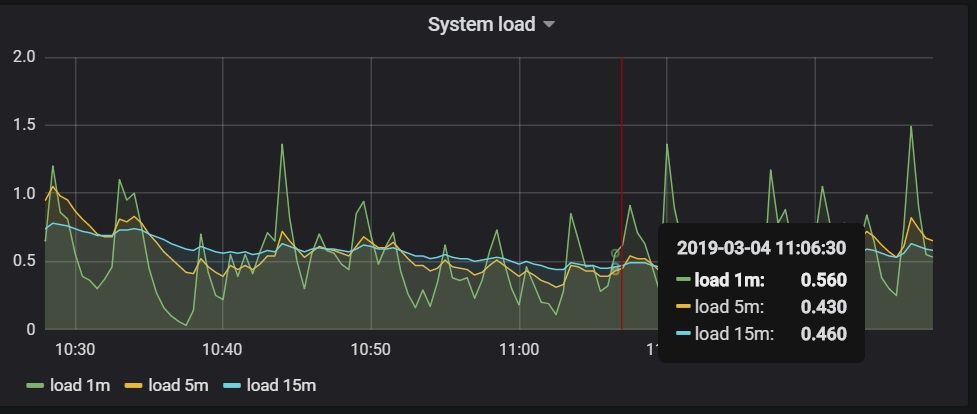
- Click any of them, for example "Node" dashboard will list all performance metrics
6 Summary
Above setup should make the kubernetes cluster monitoring/alerting/logging up and running, this solution could be applied to a small/middle sized kubernetes cluster as well if it is self-hosted.